In Python, there are a lot of things you can do with strings. In this cheat sheet, you’ll find the most common string operations and string methods.
String operations
len(string) Returns the length of the string
for character in string Iterates over each character in the string
if substring in string Checks whether the substring is part of the string
string[i] Accesses the character at index i of the string, starting at zero
string[i:j] Accesses the substring starting at index i, ending at index j-1. If i is omitted, it's 0 by default. If j is omitted, it's len(string) by default.
String methods
string.lower() / string.upper() Returns a copy of the string with all lower / upper case characters
string.lstrip() / string.rstrip() / string.strip() Returns a copy of the string without left / right / left or right whitespace
string.count(substring) Returns the number of times substring is present in the string
string.isnumeric() Returns True if there are only numeric characters in the string. If not, returns False.
string.isalpha() Returns True if there are only alphabetic characters in the string. If not, returns False.
string.split() / string.split(delimiter) Returns a list of substrings that were separated by whitespace / delimiter
string.replace(old, new) Returns a new string where all occurrences of old have been replaced by new.
delimiter.join(list of strings) Returns a new string with all the strings joined by the delimiter
파이썬 공부를 어떻게 할까 고민하던 중 구글에서 IT Automation with Python이란 강의를 내놓았다는 사실을 접하게 되었다. IT Automation with Python 강의 커리큘럼이 내가 학습하고 싶었던 내용들이라 기존의 계획을 버리고 IT Automation with Python강의를 수강하기로 결정했다.
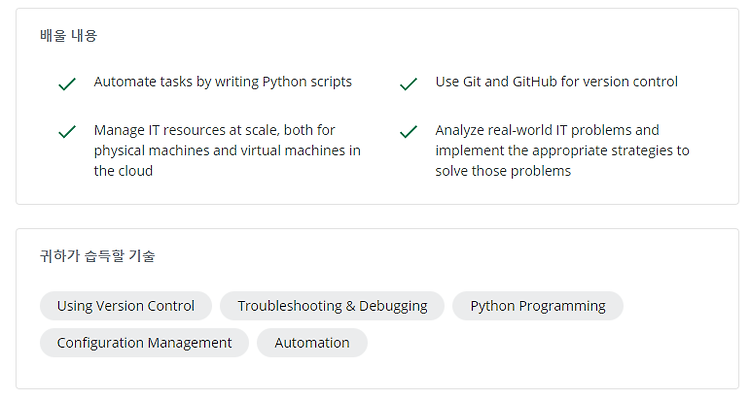
강의 사이트에 나와있는 배울 내용이다.
6개의 코스는 다음과 같다.
1. Crash Course On Python
2. Using Python to Interact with the Operating System
3. Introduction to Git and GitHub
4. Troubleshooting and Debugging Techniques
5. Configuration Management and the cloud
6. Automating Real-World Tasks with Python
강의는 총 6개의 코스로 구성되어 있고 IT 전문가에게 Python, Git 및 IT 자동화 기술을 제공하기 위해 설계되었다고 한다. Python으로 프로그래밍하는 방법과 시스템 관리 작업을 자동화하기 위해 Python을 사용하는 방법을 알려주고, Git과 GitHub, 디버깅 기법 그리고 클라우드에서 자동화를 적용해 설정관리를 하는 것까지 알려준다.
처음 시작시 7일간 무료로 이용할 수 있고 무료기간이 종료 후 등록한 신용카드에서 1달에 $49 가 결제된다.
강의를 다듣고 나면 Linked in에 등록가능한 자격증을 공유 할 수있다고 하니 열심히 들어보아야겠다.
현재 1. Crash Course on Python, 2.Using Python to Interact with the Operating System을 끝낸 상태이다.
1코스에서는 파이썬의 기초문법에 관해서 학습한 후 연습문제를 통해 코드를 직접 작성할 수 있게 해준다. 그냥 혼자 책으로 봤을 때와는 달리 문제를 풀어야 다음 강의로 넘어갈 수 있기 때문에 이점은 참 좋은 것같다.
2코스에서는 python moule을 통한 스크립트 작성과 bash scripts에 대해서 배울수 있다. 2코스 역시 문제를 풀어야 다음 강의로 넘어갈 수있기 때문에 효과적이고 강의 마지막 부분에 qwiklab을 통한 실습을 따라 해볼 수 있는데 이부분이 마음에 들면서도 가끔식 문제에서 말하는 output이 제대로 출력되지만 채점이 제대로 되지 않을 때가 잇다....... 밤 중에 하다가 채점이 제대로 되지않아 상담를 요청하기도 했다. 결과 스크린샷을 첨부해 줬더니 상담사가 과제 통과 표시를 해줬다.
코스 중간중간 강의가 끝나면 python documention 사이트나 해강 강의에서 배운 내용을 더 심화적으로 정보를 얻을 수 있는 사이트들을 알려준다.
자동화 스크립트를 위해 처음 파이썬을 배우고자 한다면 좋은 강의인 것 같다. 물론 더 심화적인 내용을 학습하기 위해선 다른 사람의 파이썬 스크립트를 보고 학습하거나 별도의 다른 노력이 필요하겠지만 기초부분을 잡기엔 주변사람들에게 추천해줄 수 있을만한 강의이다.
본 세션에 들어오신 분들은 컨테이너 도커에 대해서 잘알고 계실겁니다. 쿠버네티스에 대해 간단히 집고 넘어가자면 2014년에 오픈소스로 공개된 프로젝트입니다. 15년이 넘는 시간동안 대규모의 워크로드에 대한 운영노하우가 집결된 오케스트레이션 툴로서 원래는 이름은 보그라고 불렸습니다. 그래서 처음에 컨테이너 내지는 쿠버네티스 오케스트레이션툴을 고민하셧던 분들은 쿠버네티스는 들어본지도 얼마되지도 않았는데 우리 프로덕트에게 사용하기에 머추얼 합니까 물어보시는 고객분들이 계십니다. 하지만 쿠버네티스는 오래전부터 개발되어왔고 오랜 시행착오를 거쳐서 C&CF에서 완벽하게 인큐베이팅을 끝낸 그래듀에이트 프로젝트 프로그램으로 선정되었습니다. 그래서 쿠버네티스는 우버나 블롬버그 뉴욕타임즈 이베이 골드만삭스 이러한 이름만 들어도 알수 있는 유수의 기업들에서 컨테이너의 오케스트레이션툴로써 이미 사용되고 있고 포츈 100대 기업의 71퍼센트 이상이 컨테이너 환경을 이용하고 있으며 51퍼센트 이상은 오케스트레이션 툴로써 쿠버네티스를 사용하고있습니다.
쿠버네티스는 그럼 무엇일까요? 단순히 닷커하고 쿠버네티스하고 또 닷커스웜하고 무슨 관계일까요?? 쿠버네티스는 첫번째 오픈소스 컨테이너 관리 플랫폼이라는 점입니다. 닷커컨테이너는 컨테이너 그 자체라고 한다면 쿠버네티스는 컨테이너를 관리해주는 플랫폼 인거죠. 컨테이너가 보다 손쉽게 서비스로서 디플로이 플랫폼으로서 컨테이너를 배포하고 확장하는것에 손쉽게 이용할수 있는 툴로써 사용가능합니다. 그리고 쿠버네티스는 여러분들께서 기본요소로써 응용프로그램구축을 위한 기본요소로 사용되어지기 때문에 여러분들이 설정하고 관리하고 운영하시는거에 큰 비용과 개발하기위해 들어가는 노력들이 그다지 많이 필요하지않습니다. 물론 쿠버네티스가 복잡하게 느껴지실수 있습니다. 그러나 쿠버네티스가 복잡하게 느껴지실수 있는 이유는 기존과 다른 접근 방식으로 컨테이너라던지 어플리케이션 빌드 디플로이 환경을 접근하기 때문에 생소함에 있어서 발생하는 문제이지 컨테이너 쿠버네티스 자체가 그렇게 복잡하지는 않습니다.
여러분들이 잘알고 계신 닷커파일을 한번 보겠습니다. 닷커파일을 한번 보시면 어느이미지에서 가져오는지에 대한 정보가 있고요. 이것들을 라벨을 통해서 이미지를 컨트롤합니다. 그리고 이것들이 어떠한 포트로 expose되는지를 설정하고 이것들을 빌드하게 되죠. 이렇게 되면 어떤일이 일어날까요. 닷커에서 어플리케이션이 이미지화되고 이것들이 이미지로 저장된다음 컨티이너로 라이징해서 여러분의 어플리케이션이 손쉽게 배포될수 있습니다. 아까전에 쿠버네티스가 컨테이너의 배포 운영환경을 도와주는 오케스트레이션이라고 설명드렸습니다. 그런데 실제로 이게 필요한 이유는 닷커를 어플리케이션으로 패키징하고 난 이후에 빌드하고 디플로이 하는 일련의 과정속에서 여러분은 스토리지를 구성하셔야 하고 네트워크를 구성하여야 하고 이것들에 대한 보안설정을 하셔야합니다. 그리고 만약 스케일 아웃이 필요하게 되면 확장을 해야하고 다른 컨테이너에 연관관계들도 지정하여야 합니다. 물론 닷커가 지금 패키징 하는것만 놓고 봤을때 매우 손쉽게 설정파일을 하나로 구성할수 있었고 여러 랩탑이라던지 다양한 운영환경에서 여러분들 닷커의 portablity라는 장점으로 배포할수 있었겟지만 오히려 닷커의 포터빌리티 장점이 오히려 운영환경에서 이환경 저환경 막 왓다갓다 하다 배포하다 보면 이게 오히려 관리하기라던지 어떤 제한을 걸거나 보안을 설정하거나 이러한 것들이 더 어려울수 있다는 점입니다.
그래서 조금 쉽게 할 수 있는 방법이 있습니다. 뭐냐면 닷커 컴포즈 파일입니다. 닷커 컴포즈 파일에서는 네트워크 설정이라던지 여러닷커간에 연관관계에 대해서 설정할수있습니다. 그래서 닷커파일이 하나가 있으면 이 닷커파일에 대해서 만약에 웹하고 레디스를 연결한다 치면 닷커컴포즈 파일에서 이렇게 두개의 닷커이미지에 대한 설정을 닷커컴포즈에 대한 파일을 다 넣어놓고 다커 컴포즈를 업해서 여러분들의 어플리케이션이 배포되는 형태로 운영하실수 있었습니다. 닷커 컴포즈 파일만 해도 닷커파일만 해서 사용하는것보다 쉽겟죠 왜냐면 닷커파일만 사용해서 개발하셧다면 지금 이환경에서 닷커컴포즈 파일에 지정된 두개의 닷커 이미지에 대한 두개의 닷커파일과 그다음 스토리지 네트워크 연결설정들을 별도로 해주어야 했기 때문입니다. 그런데 여기서 끝나는것이 아니라 여러분들이 어플리케이션을 배포해서 운영하게 된다면 스케일아웃 내지는 이 닷커갯수를 더 증가시킨다던지 내지는 네트워크 설정을 변경한다던지 이러한 설정들이 있을수 있겟습니다.
이러한 경우에는 바로 쿠버네티스를 이용하여서 여러분들이 설정을 조금더 간편하게 하실수 있습니다. 첫번째는 gowebapp이라는 yaml파일을 하나 만들었습니다, 이거는 쿠버네티스에서 이미지를 가져와서 배포할수 있게 설정한 내용들이 포함되었고요 이제 이 이미지에 대한 디플로이먼트 설정을 합니다. 여기서는 디플로이먼트 종류가 무엇진이 레이블을 어떻게 해서 관리하는지 그리고 네트워크에 연결할건지에 대해서 라벨들을 설정하고 구성을 하게 됩니다. 이렇게 설정파일만 만들어놓으면 여러분들은 쿠버네티스 클러스터에서 어플리케이션을 디플로이 하거나 서비스를 레디 시킬때까지 다른 설정이 필요하지 않습니다. 바로 이 설정파일을 불러와서 kubectl apply -f <설정파일 path>를 지정해주시면 자동으로 컨테이너 이미지를 가져와서 쿠버네티스 클러스에서 서비스 디플로이를 배포하게 되어있습니다. 그래서 간편하게 서비스를 배포하신 내역을 kubectl get service OR get deployment 해서 여러분들의 배포환경이라던지 서비스 상태를 확인하실 수 있습니다.
쿠버네티스가 확실히 닷커를 좀더 편리하게 사용할수 있게 해주는 툴이라는 것은 여러분들이 이제 간단한 에제를 통해서 보셧을 것이라 생각합니다. 그러면 쿠버네티스 말고도 다른 오케스트레이션 툴이 있는데 왜 쿠버네티스가 그렇게 많은 고객들, 유저들에게 환영받고 있는걸까요, 첫째 쿠버네티스는 각각의 사용자들 특히 성장하는 사용자들을 커뮤니티와 그 커뮤니티에 기여하는 사용자들을 대상으로 대게 같이 성장해 나가고 있습니다. 쿠버네티스 프로젝트는 150만개의 프로젝트 중에서 약 9번째로 커밋숫자가 많고 그리고 기여자의 숫자는 리눅스 커널 다음으로 두번째로 많은 큰 프로젝트 입니다. 그래서 쿠버네티스의 경우에는 단순히 오케스트레이션 툴을 뛰어넘어서 사용자와 개발자가 함께 만들어나가는 공동 커뮤니티가 되었습니다. 그리고 쿠버네티스는 단순히 오느소스 내지는 퍼블릭 클라우드에서 컨테이너를 제공하는 컨테이너로 활용하는 클러스터 플랫폼을 뛰어넘어 온프레미스와 퍼플릭 클라우드를 연결해서 하이브리드 클라우드의 새로운 모델로 제안되고 있습니다. 또한 쿠버네티스는 단일확장 API를 이용해서 확장과 성능 이러한 것들을 여러분들이 좀더 스케일 아웃하고 여러분들이 예측가능한 형태로 확장하고 다양한 플러그 인들과 애드온들을 이용해서 여러분들이 보다 손쉽게 이용할수있는 툴로써 개발되어지고 있습니다.
앞서서 쿠버네티스 설정파일에 대해서 설명을 했지만 실제로 여러분들이 쿠버네티스를 운영하시면서 생각실제로 디플로이를 할것이며 쿠버네티스의 yaml파일이 생각보다 복잡해질수 밖에 없다는 사실에 놀랄수 잇습니다. 처음에 닷커 파일이나 닷커 컴포즈 파일은 각각의 닷커 이미지나 어플리케이션에 대한 설정만 나타냈다면 쿠버네티스에 대한 나타냈다면 쿠버네티스에 대한 디플로이먼트 서비스 이러한 설정파일들을 네트워크 팔리시 그리고 스토리지 설정 이것들 뿐만이 아니라 여러분들이 어플을 배포하거나 컨피그 맵이라던지 여러분들이 빌드 설정 같은 것들도 같이 들어가야 하기 때문입니다. 그러면 하나의 설정파일 안에는 많은 내용이 들어가게 되고 설정파일에 만약 오타가 발생한다면 어떻게 디버깅 할수 있을까요 되게 복잡해 지겟죠? 그래서 쿠버네티스의 설정파일 또한 관리해주기 위해서 헬름이나 큐브팩 같은 애드온 프로그램을 이용해서 여러분들이 설정파일을 일일이 택스트파일로 관리하는것이 아니라 애드온을 이용해서 손쉽게 이용할수 있는 플러그인들도 유저들사이에서 같이 개발되어 지고 있습니다. 특별히 쿠버네티스는 AWS에서 같이 많은 작업들을 하고있고 AWS에서 디스팅기쉬 엔지니어들이나 AWS에 있는 오픈소스 커뮤니터들이 같이공동 개발하면서 약 51%의 쿠버네티스 워크로드를 AWS에서 운영하고 있습니다.
전세계 쿠버네티스 워크로드 51%를 AWS에서 운영되고 있고 그러다 보니 가장 많은 테스트 가장많은 유즈 케이스를 AWS가 가지고 있다라고 보시면 되겠습니다. 먄약에 쿠버네티스 클러스터를 이용해서 프로덕션이라던지 서비스를 여러분들이 배포하신다고 하면 가장 많은 유즈 케이스를 가장 많은 데이터를 가진 플랫폼에서 여러분들이 배포하시는 게 시행착오를 줄일수 있는 가장좋은 방법일것입니다.
쿠버네티스 클러스터를 셋업하기 위해선 다양한 방법들이 있을수 있는데 특별히 여러분들이 쿠버네티스를 개발할때 로컬에서 minikube를 이용한 개발을 내지는 테스트를 해볼수있습니다. 이것은 싱글로드 쿠버네티스 클러스터로 여러분들이 쿠버네티스의 큐브파일에 쿠버네티스 설정파일을 설정했을때 이것들이 과연 정확하게 설정됫고 정확하게 디플로이 됬고 그리고 어플리케이션이 잘 구성되있는지 테스트해볼수있게 해주는 아주가벼운 쿠버네티스 클러스터를 여러분들의 랩탑이나 로컬머신에서 실행할수있는 환경을 제공합니다. 그리고 최근들어서 닷커에 커뮤니티 에디션에 닷커온 맥버전에서는 쿠버네티스가 싱글로드 쿠버네티스가 로컬호스트의 클러스터로 내장되게 되어있게 되어있습니다. 그래서 여러분들은 쿠버네티스 클러스터를 별도로 설치할 필요없이 맥에서 그냥 쿠버네티스의 설정파일이라던지 쿠버네티스의 디플로이먼트를 로컬머신에서 테스트해보고 바로 스테이징내지는 프로덕션으로 넘길수있는 옵션들을 가지시게 됩니다. 그리고 또한 각각의 밴더에서 제공하는 클라우드 프로바이더 들이 제공하는 매니지 서비스를 제공하지 않고 온프레미스와 동일하게 쿠버네티스 클러스터 마스터 노드를 운영하시고자 하는 고객들을 위해 오픈소스에서 커뮤니티에서 개발하고있는 쿠버네티스 오퍼레이터 KOPS라는 CLI명령도 존재합니다.
이것뿐만일 아니라 쿠버네티스는 엔터프라이즈 소프트웨어가 가능한 IT벤더들에서 제공하고있던 솔루션도 있었습니다. 테크톤이 내지는 오픈 쉬프트 들이 그러한 것들이었습니다. 이러한 것들도 AWS위에 올려서 바로 사용하실수 있고 오늘설명드린 쿠버네티스, 매니지드 서비스인 EKS라고 해서 AWS에서 제공하는 서비스를 이용할수도있습니다. 쿠버네티스를 이용할때 아까와 같은 설정뿐만 아니라 인증이나 보안설정 이러한 설정들도 자동화 해주는툴도 필요합니다. 특별히 이미지를 ECR라던지 여러분들이 이미지를 레포지 스토리지에 자동으로 등록을 하고 권한이나 롤 폴리쉬에 맞게 이 이미지를 가져갈수있게 설정하기 위해서는 여러분들이 인증 자동화 플러그인들도 사용하실 필요가 있습니다. 이런것들은 Heptio라던지 EKS를 더욱 쉽게 사용할수 있는 자동화 툴인 EKSCLI같은 경우는 waveworks와 함께 개발하고 제공해 드리고 있습니다.
지금 화면에 보시는 내용은 이제 쿠버네티스 클러스터를 KOPS로 생성할때 입력해야하는 CLI명령입니다. 첫번째는 어느 AZ에 쿠버네티스 클러스터를 전개할지 지정하시고 쿠버네티스의 스테이터스 파일 그러니까 서버의 쿠버네티스 마스터 노드의 스테이터스의 파일을 저장해서 이것을 백업해 여러분들이 다른 클라이언트에서도 접속할수있게끔 정보를 보관하는 별도의 S3버킷을 지정한 다음 쿠버네티스 클러스터를 배고하게 됩니다. 각각의 파라미터들은 마스터 클러스터의 카운터, 어떤 인스턴트 사이즈로 마스터를 배포할지, 이런것들이 어느 리전에 대포될지, 네트워킹은 어떤 모델을 사용할지 이러한 것들을 지정하게 됩니다. AWS EKS를 사용하게 되면 이러한 부분들에 대해 자동화되서 여러분들이 단순하게 리전하고 프로파일만 선택하시게 되면 AWS CLI의 프로파일 설정내역을 읽어서 간단한 명령으로 배포할수있게 됩니다.
그래서 EKS는 관리형 쿠버네티스 컨트롤 플래인 으로써 고가용성 API서버와 ETCD를 제공하고 있기때문에 자동화된 쿠버네티스 마스터노드 클러스터를운영 하실수 있게 됩니다. 특별히 EKS를 이용하게 되면 기본적으로 여러분들이 클러스터를 배포하는 시점에 여섯개의 인스턴스가 자동으로 준비가 되게 됩니다 그래서 마스터 노드의 클러스터를 운영하기 위한 세개의 인스턴스가 세개의 멀티헤더로 운영이 되게 되고 나중에 세개의 인스턴스는 ETCD로써 각각의 AZ에 배포되는 인스턴스 내지는 컨테이너의 정보 상태를 관리하게 됩니다.
그럼 다음으로 EKS에 대해서 자세히 알아보겠습니다.
EKS는 크게 4가지 Tenets이 있다고 말씀드리고 있습니다. 첫번째는 쿠버네티스입니다. EKS는 쿠버네티스 매니지드 서비스라고 하는데 왜 쿠버네티스를 강조할까요? 그냥 쿠버네티스가 유사한 API를 통해서 유사하게 컴페러빌리티를 적당히 제공합니다가 아니라 100% 여러분들이 사용하시는 오픈소스 쿠버네티스와 동일한 환경을 제공한다는 것입니다. 저희들이 오픈소스 프로젝트를 이용해서 실제로 AWS에서 서비스하는 여러가지 서비스들이 있습니다. Elactic search라던지 다른 서비스들이 있습니다. 일부 서비스들은 저희들이 오픈소스와 약간 다른 버전들을 유지하고 성능을 최적화해서 유지하는 경향이 있습니다. 서비스에 더욱알맞게 서비스 하기 위해서죠, 하지만 쿠버네티스 자체가 이미 되게 머츄얼한 솔루션이고 이것들이 커뮤니티에서 이미 인정을 받았기때문에 쿠버네티스 클러스터 자체를 그대로 업스트림 내지는 오픈소스 쿠버네티스와 완벽히 동일한 API를 제공할 수 있게끔 첫번째 목표입니다. 두번째는 업스트림 쿠버네티스를 지원합니다. 그럼 첫번째 그냥 쿠버네티스와 완벽히 동일한 쿠버네티스를 지원한다는 것과 업스트림 쿠버네티스를 지원한다는 것은 어떻게 다를까요? 그건 최신 쿠버네티스를 항상 업데이트 해서 여러분들께 제공한다는 것입니다. EKS를 사용하시는 고객들은 오토 업데이트 기능도 같이 제공을 해서 여러분들의 마스터 노드가 항상 최신버전의 쿠버네티스를 사용할수 있도록 사용환경을 제공한다는 것입니다.
그리고 세번째는 쿠버네티스가 단순히 스테이징이라던지 개발환경으로 사용되는 것이아니라 엔터프라이즈 환경에서 사용될 수 있도록 가용성과 확장성을 제공한다는 것입니다. 마지막으로 다른 AWS 서비스와 완벽하게 통합된다는 것입니다.
시관관계상 많은 내용을 다룰수는 없지만 쿠버네티스를 이용할때 고객분들이 많이 얘기하는 다양한 어려움들이 있습니다. 첫번째는 네트워크 두번째는 스토리지 세번째는 디버깅 이러한 부분들이 있습니다. 그리고 로깅 모니터링 부분도 존재합니다. 이런 것들을 위해서 AWS 서비스들이 인티그레이션 된다는 얘기는 첫번째 AWS 엑스레이 같은 것들을 이용해서 쿠버네티스의 배포되어있는 여러분들의 어플리케이션들을 좀더 손쉽게 디버깅하고 그리고 여러분들의 마이크로 서비스 아키텍처가 어떤식으로 운영되고 서비스 되고 관리 되고있는지를 한순에 볼수있는 뷰를 제공합니다. 두번째는 로깅같은 부분에서 분산로깅 시스템에서 여러분들이 로깅스토리지 로깅크러스터를 직접 운영하실 필요가 있는게 아니라 클라우드 왓치 로그를 이용하시거나 Elastic search를 이용하시거나 플론트 D같은 것들을 이용하셔서 여러분들의 로깅 클러스터를 직접 관리하시지 않고 매니지드 서비스를 사용하실수 있다는 것입니다. 그리고 세번째는 플론트 D같은 것들을 이용하시면 여러분들의 로깅데이터를 S3에 저장하실수 있습니다. 이렇게 되면 많이 쌓인 로그들을 저희 아티에나나 레드쉬프트 스펙트럼을 사용해 분석할수도 있고 이런 분석된 데이터를 가지고 새로운 인사이트를 추출할 수잇는 별도의 빅데이터 플랫폼으로써 사용할 수 있습니다.
EKS 아키텍처는 아까전 간단히 말해드렷듯이 이러한 형태입니다.
각각의 AZ별로 API서버와 ETCD와 그 가용영역에서 서비스하는 인스턴스들이 배포되게 됩니다, 각각의 API서버들은 서로 HA형태의 클러스터를 운영하게 되고 이것들을 실제로 고객분들께 보여지지는 않습니다. 그냥 하나의 마스터 엔드포인터로 이렇게 보여지게 됩니다.
그래서 여러분들께서는 mycluster.eks.amzonaws.com이라는 앤드포인트로 EKS를 배포하셧다면 여기에 단일 앤드포인트에서 여러분들의 EKS의 워크로드들을 운영하시기만 하면 됩니다. 그래서 여러분들이 쿠버네티스 설정파일로 만들어 놓앗던 설정 그 컨테이너 쿠버네티스 어플리케이션들이 그냥 단일 컨트롤 플래인 단일 API서버에 의해서 마치 운영되는 것처럼 여러분들이 어플라이 하시고 배포만 하시면 바로 어플리케이션이 서비스화 되서 디플로이되는 이런 서비스를 이용하실 수 있게 됩니다.
기본적으로 EKS를 사용하시는 고객분들께서는 첫번째 EKS클러스터를 생성하고 워커 노드를 생성하고 이것을 클러스터에 추가하여야 합니다. 그러고 나서 고객이 고객환경에 맞게 애드온들을 추가하고 워크로드를 실행하는 크게 4가지 스텝을 밟아 나가게 됩니다. 만약에 처음에 EKS를 생성하게 되면 저희 AWS사이드에서 쿠버네티스 클러스터를 생성하기 위해서 이런 작업들이 수행되게 됩니다.
첫번째는 쿠버네티스의 API서버를 구성하고 그에 각각의 AZ에 배포되게 되고 그 API서버의 데이터 그리고 쿠버네티스 상태정보를 저장하기 위한 ETCD가 구성되서 AZ에 같이 배포되게 됩니다. 그리고 나서 API서버에 들어오는 API콜들 그러니까 쿠버네이스에 오는 API에 대해 롤이라던지 적절한 권한 폴리쉬에 맞게 수행되는지를 볼수 있게끔 IAM을 구성하게 되고 여기에 대한 인증을 설정한 다음 마스터 노드들 쿠버네티스 클러스터에 헤더 노드들이 오토스케일링 되도록 자동으로 구성되게 됩니다. 그러고 여기에 연결될수 있도록 네트워크 로드밸런서가 구성되고 여러분들의 클러스터가 안정적으로 구성되게 됩니다. 그런데 여기서 EKS 클러스터가 생성되고 나서 고객분들이 워커노드를 생성해서 붙여야 합니다. 이작업은 워커노드를 커스터마이징 하셔서 여러분들이 원하는 워커로드를 붙일수 있다는 애기도 되지만 굳이 워커노드를 생성해서 붙이는 작업을 하고싶지 않으신 고객들 이 작업 자체가 부담스러운 고객들 한테는 오히러 작업부하로 다가올수 있겠죠. 그래서 이러한 것들을 위해서 EKS CTL을 제공하고 있습니다.
여러분들께서는 이제 간단하게 명령어 한줄로 EKS CTL을 설치할 수있고요 이것들을 이용하면 EKS CTL을 이용해서 클러스터를 생성하는 동시에 바로 이렇게 노트 타입 c4.xlarge 30개 노드를 클러스터에 추가할 수 있습니다. 그리고 30개 추가한 내역을 40개로 한번의 명령을 통해서 확장하실수 있고 이렇게 되시면 클러스터 사이즈를 한두번의 명령어로 확장 축소할 수 있는 좀더 편리한 기능을 제공합니다.
P2인스턴스는 cpu인스턴스 입니다. 만약에 쿠버네티스에서 kubeflow라던지 텐서플로우 같은 어플리케이션 특히 그래픽 가속기능을 이용하는 어플리케이션을 배포하시는 경우에 EKS용 최적화되어있는 GPU인스턴스 AMI가 있습니다. 이것들을 이용해서 클러스터를 배포하시게 되면 GPU인스턴스를 이용해서 어플리케이션을 가속화시킬수 있습니다. 이때는 이렇게 Nvidia에서 제공하는 쿠버네티스 플러그인만 추가하면 여러분들이 사용할수 있게 됩니다.
EKS아키텍처는 이렇게 되어 있습니다. 워커노드들이 있고 EKS클러스터를 여러분들이 처음 생성하실때 컨트롤 플래인이 생성됩니다. 이때 NLB를 통해서 API를 호출하게 되면 마스터 플래인 즉 컨트롤 플레인에서 워커노드와 통신을 하면서 튜블랫으로 통신을 하면서 여기에 컨테이너를 올리고 하드를 관리하는 이러한 오퍼레이션이 이루어지게 됩니다. 이러한 것들은 여기 각각의 배포되어있는 인스턴스의 ENI를 통해 통신이 되게 되고 각각의 통신은 TLS를 통해서 암호화 되서 전송되기 때문에 안전하게 통신되게 됩니다.
로깅 & 모니터링에 대해서도 간단히 설명드리겠습니다.
닷커 로깅 드라이버가 생각보다 많습니다. 일반적으로 닷커 로깅은 스탠다드 아웃풋을 이용해 화면에다가 뿌릴수도 있지만 파일에도 쓸수 있고 플루언트딜을 이용해서 내지는 레디스라던가 스플렁크 같은 것을 이용하거나 아예 서드파티툴을 더 확장해서 뉴렐릭이라던지 스모로직을 이용할수도 있습니다.
기본적으로 닷커 로깅 드라이버는 저희들이 EKS내지는 닷커 엔진 자체에서 제공하는 닷커드라이브들을 제공하고있습니다. 특별히 닷커로그에서 닷커를 배포하실때 닷커 run 하시는 상황에서 파라미터로 로그드라이버를 파일로그 드라이버를 파일로그 드라이버를 이용할수도 있고 플루언트 딜을 이용해서 특정 클러스터에다가 로그를 전송하도록 지정할 수 있습니다. 특별히 ECS에서는 그런 로그 드라이버를 다양하게 지원하고있습니다. 그러면 쿠버네티스에서는 어떻게하는게 좋은가? 만약 쿠버네티스에서 마이크로 서비스 아키텍처에 다양한 파트들이 인스턴스에 수십개씩 올라가 있는데 이 파트들의 로그를 인스턴트에 특정파일에 같이 쓰기 시작한다면 여기에 파일을 쓰기 시작했을때 IO부하를 이 인스턴스가 과연 견뎌낼수 있을까요? 여러분들이 마이크로 서비스 아키텍처에서 파드가 되게 복잡하게 확장되는 시점에 로그를 모으는 것자체도 생각보다 쉽지않은 기술적인 도전과제일 수 있습니다. 그래서 C&CF에서는 이러한 쿠버네티스의 로그 어그리게이션아키텍처로써 제인 되는게 플루언트 디와 , 엘라스틱서치, 키바나 이모델입니다.
그래서 아마존에서는 아마존 EKS에 플루언트 디를 이용해서 이렇게 로그를 모을수 있는 로그 어그리게이션 아키텍처를 제안하고 있고 플루언트디의 아키텍처는 기본적으로 가운데에 있는 풀루언트디가 로그데이터를 모아서 소스 1,2,3 다양한 소스에 있는 로그들을 플루언트 디에서 모아서 플루언트 디에서 JSON형태로 모으기도 하고 컬럼 형태로 모아서 커스텀 필더로 만들어서 스토리지 영역에 바이패스 하게끔 되어있습니다. 스토리지 영역은 엘라스틱 서치일수도 있고 S3일수도 있고 여러분들이 지정하신 스토리지 영역이 되겠죠. 그리고 이것들은 데이터가 들어온 시점에 여러분들의 특정한 판단 또는 필터를 걸어서 데이터를 전송되게끔 할수도 있습니다.
엘라스틱 서치와 키바나의 모델은 저희가 이렇게 보시는 것처럼 EKS 클러스터가 있다면 각각의 인스턴스에 플루언트디가 데몬셋형태로 배포가 되서 인스턴스 하나하나당 플루언트디가 있고 거기서 배포되어 있는 어플리케이션들의 스탠다드 아웃풋으로 나오는 로그들을 플루언트 디가 엘라스틱서치에 전송하게되고 이 전송된 엘라스틱 서치의 로그들은 커스텀 필드라던가 필드형태로 어그리게이션 되서 키바나에서 보여주는 형태로 비주얼라이션 되게 되어 있습니다.
플루언트 디의 데몬셋 디플로이는 이렇게 여러분들이 쿠버네티스의 설정파일에서 간단하게 데몬셋해서 플루언트디 클러스터를 만들고 여기서 모니터링 전송할 데이터 엘라스틱 서치의 포트, 주소를 지정하면 이렇게 엘라스틱 서치쪽으로 연결되서 여러분들이 설정하실수 있게 되어있습니다.
특별히 쿠버네티스 모니터링을 할때 헷갈려 하는 부분중에 쿠버네티스는 모니터링 할 내역들이 매우 많다라고 생각할수 있습니다. 쿠버네티스는 특별히 3가지 정도의 모니터링 리소스가 있습니다. 첫번째는 리소스 매트릭 파이프라인이라고 해서 kubelet과 cAdvisor로 구성되어 있는 놈입니다. 이것은 각각의 쿠버네티스의 노드들 상태정보, 거기서 사용하고 있는 CPU,mem,network, 디스크 사용량 정보를 마스터 노드로 전달하게 되어있습니다. 그렇지만 이건 인스턴스에서 그 파드 사용하고있는 전체 사용량이지 각각의 어플리케이션 사용량은 아니기 때문에 여러분들이 원하시는 어플리케이션이나 서비스에서 사용하는 형태의 모니터링을 하시기 위해선 바로 Full metric pipeline이 필요합니다 이때는 프로메테우스를 이용해서 모아서 사용하시면 되겠습니다. 그리고 여러분들이 일반적으로 쿠버네이스의 대쉬보드에서 보시는 내용은 cronjob monitoring이라고 해서 전체 클러스터의 상태정보를 polling형태로 화면 리프레시해서 보여주는 형태 이 3가지 형태가 있습니다.
그래서 쿠버네티스에서는 여러분들이 서비스 라던지 어플리케이션을 모니터링 하기위해선 프로메테우스가 필수적으로 필요하게 되고요. 이 프로메테우스는 플루언트디라던지 다양한 kubelet이라던가 플루언트디, cAdvior같은 데이터들을 이용해서 프로메테우스에 모으게 되고 이 프로메에우스에 모으게 된 데이터를 grafana라던지 대쉬보드 형태로 보여주게 되서 원하는 형태의 데이터를 모을수 있게 되는 것입니다.
강의가 끝나고 저희가 제공하고 개발하고 있는 EKS workshop을 한번해보시기를 추천드립니다. EKS workshop은 지금 AWS에서 컨테이너 AOD를 갖고있는 엔지니어들과 그리고 고객의 피드백을 바탕으로 같이 개발해 나가고 있고 여러분들이 쿠버네티스를 이용하면서 어려웠던점 그리고 좀더 잘 활용하기 위해서 알고싶엇던 점들에 대해서 저희들에게 피드백을 주시면 workshop컨텐츠로 개발해 고객분들께 전달해 드리겠습니다. https://eksworkshop.com/
안녕하세요 AWS 솔루션 아키텍트 이창수 매니저입니다. 저는 스토리지와 오토스케일링에 대한 다양한 쿠버네티스 옵션에 대해서 설명을 드리겠습니다. 먼저 스토리지에 대해서 살펴보겠습니다.
일반적으로 컨테이너의 볼륨을 크게 3가지로 나누어 보면 컨테이너 이미지 자체에 포함된 볼륨, 컨테이너가 배포가 되는 호스트에 있는 볼륨을 사용하는경우, 호스트의 있는 볼륨이 아니라 컨테이너와 네트워크를 통한 다른 볼륨을 데디케이트하게 연결해서 사용하는 3가지 케이스가 있을수 있습니다. 먼저 컨테이너에 있는 볼륨은 그 임시로 사용하는 볼륨들이 있기때문에 컨테이너가 종료가 되면 손실이 될수 있습니다. 호스트에 있는 볼륨을 사용할때는 컨테이너가 다른 호스트 재배치가 되면 다른 EC2인스턴트에 재배치가 되면 기존 호스트에 있는 볼륨을 바라볼수가 없기때문에 접근이 불가하게 됩니다. 마지막으로 세번째로는 네트워크 볼륨이 있는데 호스트에 독립적이기 때문에 컨테이너와 다른쪽으로 스케쥴링이 되더라도 그래도 사용할수 있습니다.
temp, host, network세가지 볼륨으로 나누어서 보면 먼저 볼륨 타입중 emptyDir이라는 temp볼륨을 사용하는 타입이 있습니다. 쿠버네티스를 정의할때보면 볼륨 부분이 있습니다. 여기서 볼륨타입에 따라서 사용할수 있는 볼륨을 선택할수 있는데 emptyDir을 사용하면 그 컨테이너가 배포가 되는 호스트에 있는 메모리캐쉬를 임시를 사용하는 볼륨이라고 생각할수 있습니다.
그리고 gitRepo도 사용할수 있습니다. 이것도 마찬가지로 기본적으로는 임시로 사용하는 볼륨이고 정의하실때 gitrepo로 하시면 어떤 static파일이나 scripts source들을 동적으로 배포하실때 활용하실수 있습니다,.
그리고 hostPath는 배포가 되는 호스트에 있는 파일 시스템이나 어떤 파일들을 컨테이너에 마운트해서 사용하는 형태라고 생각할수 있습니다. 기본적으로 컨테이너 이미지를 만들때는 컨테이너 이미지를 최대한 경량화해서 만드는 것을 권장을 드립니다. 어차피 컨테이너가 호스트에 배포가 되서 사용이 되는데 호스트에 있는 파일셋들을 그 컨테이너가 사용이 가능하다면 굳이 컨테이너에 포함할 필요가 없기때문에 그럴경우에 이렇게 호스트패스를 사용하시면 이미지를 경량화시킬수 있고 하나의 호스트에 배포되는 여러 팟들이 호스트에 있는 특정 파일시스템이나 파일을 같이 공유해서 바라볼수 있습니다. 하지만 이제 여러팟들이 하나의 호스트 배포가 됬을때 모든 팟들이 기존에 있던 호스트 볼륨을 수정하거나 지우거나 했을때 문제가 생길수도 있기때문에 privileged로 생성된 컨테이너만 저 호스트 패스를 수정하거나 지우는게 가능하게 됩니다.
이러한 임시볼륨과 호스트볼륨은 제약이 있습니다. 그래서 stateless 어플리케이션에 적합합니다. 컨테이너의 네이티브한 특성을 살려서 어느쪽으로 배치가 되던지 상관없이 그대로 사용할때 적합한 볼륨이라고 생각하실수 있고. Stateful어플리케이션에 persistent한 네트워크를 통해 연결되는 호스트의 제약을 받지 않는 볼륨이 필요하게 됩니다.
저희 환경에서 보시기 전에 PV, PVC 크게 두가지로 나누어서 보실수 있습니다. PV는 독립적인 라이프 사이클을 가지고 있는 볼륨 플러그인으로 NFS, iSCSI 혹은 네트워크를 통해 제공하는 다른 클라우드 프로바이더의 여러가지 볼륨을 그대로 사용을 할수 있고. PV를 사용할때는 PVC로 먼저 해당 PV를 Claim하는것이 필요합니다. 그얘기는 PV를 생성하고 PVC에서 정의한 스펙을 기반으로 PV와 PVC가 서로 바인딩이 일어나게 됩니다. 여러분이 실제 볼륨을 프로비저닝 할실때는 스태틱과 다이나믹 두가지 방식이 있는데 뒤에서 보다 상세하게 설명을 드리도록 하겠습니다.
그래서 저희 aws환경이라고 가정을 한다면은 PV를 만드실때 그 정적인 프로비저닝 방식으로 봤을때 먼저 AWS ebs볼륨을 하나 생성을 해두시고 저렇게 pv를 만드실때 그 스펙에 보시면 AWS 엘라스틱 블록스토어라는 API가 있습니다. 저것은 쿠버네티스가 제공을 해주고있는 API고요 거기에 이제 볼륨 아이디로 저희가 사용하는 EBS의 볼륨 아이디를 넣어주시고 PV를 만드시면 기존에 있던 AWS ebs와 pv가 맵핑이 되게 됩니다. 그다음에 이제 실제 요청을 할때는 PVC라는 것을 만드셔야하는 데 PVC를 만드실때는 스펙의 억세스 모드하고 리소스의 리퀘스트 스토리지 용량이 있습니다. 그러면 여기에서 정의한 이스펙을 기반으로 기존에 있던 PV를 쿼리에서 거기에 맵핑되는 PV가 PVC와 바인딩이 일어나게 됩니다. 예를들어 십기가 짜리 PV가 있다고 가정하고 여러분은 PVC로 8기가를 요청을 하면 동일한 용량이 아니더라고 이렇게 PV가 같거나 더 큰 용량 중에서 가장 가까운걸 찾아서 맵핑이 일어나게 됩니다. 여러분이 팟을 배포할때는 보통 팟자체를 만들기보다는 팟을 컨트롤 할수 있는 리플리케이션 컨트롤러나 디플로이먼트라는 그런 오브젝트를 통해서 보통 팟을 배포하시게 되는데 그때 어떤 PV,PVC를 사용하시게 될것인지 명시하기게 되어있습니다.
억세스 모드를 PVC를 만드실때 스펙에 명시해 주시는데 크게보면 3가지가 있습니다. AWS ebs는 하나의 단일 ec2인스턴스 단위 호스트에만 마운팅이 가능하기 때문에 ebs 사용할때는 readwirteonce를 사용하셔야하고 다른 Nfs기반의 공유파일 시스템이나 이런 형태는 다른 옵션들도 같이 활용하실수 있습니다.
예를 들어 여러분이 PV굉장히 많이 있다고 가정한다면 PVC에서 특정 PV를 맵핑한다고 가정한다면 PVC에서 특정 PV를 맵핑 하는게 앞서설명드린 그 용량이랑 억세스 모드만으로는 좀 어려울수 있습니다. 그렇기 때문에 일반적으로 라벨과 셀렉터를 사용을 합니다. 그래서 PV를 보시면 메타데이터 라벨값을 넣으실수가 있는데 이제 AWS라면 저기 AZ나 ebs의 타입을 명시하실수 있을거고요 이건 그냥 메타데이터 입니다. 메타데이터로 라벨을 편의상 저렇게 작성을 한거고 PVC로 PV를 실제로 클레인 할때는 이렇게 셀렉터에서 매치 라벨에 여러분이 설정하신 그 라벨에 맞춰서 어떻게 구성을 하시면 이 라벨을 기반으로 해서 pvc가 pv를 클레인 하게 되어있습니다.
리클레인 폴리쉬는 PVC를 지우셧을때 PV가 같이 지워지도록 할건지 PV를 그대로 유지할건지에 대한 옵션이라고 보실수 있고 기본적으로는 PVC를 지우면 거기에 붙어있는 PV와 그리고 패킹 디바이스만 aws ebs나 다른 다른 블럭 스토리지도 같이 삭제되게 됩니다. 밑에는 그대로 유지하는 옵션이고요
데모를 한가지 준비를 했습니다 영상으로 준비를 했고요 먼저 ebs 아이디를 확인을 하고 ebs ID를 기반으로 PV를 맵핑해서 PV를 생성을 할꺼고요 그다음에 생성된 그 PV를 PVC와 맵핑을 할겁니다. 그러고 여러가지 샘플이 있는 저는 커즈베이스로 준비를 했고요 제 커즈 베이스 용 리플리케이션 컨트롤러를 생성을 하는 부분이고 다음에 서비스를 생성을 해서 서비스 생성 타입이 로드밸런서로 제가 선택을 했는데 이제 프로바이더를 AWS를 선택하시면 AWS 환경내에 elb가 생성이 됩니다 그러면 ELB의 DNS를 기반으로 들어가시면 ELB뒤에 붙어있는 커즈베이스 애플리케이션 컨트롤러가 작동이 되게 되어있고요. 저 리플리케이션 컨트롤러는 보통 팟을 그냥 배포했을 때는 그 팟이 죽으면 그 라이프 사이클을 관리할 수 없기 때문에 그 리플리케이션 컨트롤러의 명시한 그리플리값 숫자만큼은 다운이 되더라도 다시 자동으로 유지가 되도록 하기 위해서 사용하는 오브젝트입니다.
데모영상 40:50~45:00
어떤 스테이트 풀한 어플리케이션을 운영을 할때는 보통 PVC로 펄시스턴트 볼륨을 컨테이너 배포를 해서 사용을 하시게 됩니다. 그런데 일번적인 환경에서 이렇게 ebs를 미리 만들고 PV도 미리만들고 그것을 PVC로 메팅하고 그런게 복잡하게 느껴지실수 있는데 일반적으로 쿠버네티스를 운영하시는 분들은 다이나믹 프로비저닝을 통해서 운영을 하십니다.
이거는 그때그때 PV를 만들고 맵핑하는게 아니라 스토리지 클래스를 하나 정의해 놓으면 거기 정의해 놓은 스토리지 클래스를 기반으로 해서 그 팟을 배포할때 정의한 톨 c 클래스만 같이 정의를 하면 뒷단의 스토리지 클래스를 참고를해서 알아서 뒷단의 볼륨이 다 생겨서 맵핑이 됩니다. 그래서 그 프로비저너로는 AWS EBS가 제공이 되고있고 저 쿠버네티스.IO API에서 저희 AWS ebs를 프로비전으로 제공을 해주고 있고 여기에서 파라미터는 그 AWS ebs의 다양한 익숙하신 파라미터 일것입니다. 그래서 어떤 가용영역에 할건지 gpt로 할건지 io로 할건지 인크립션 할건지 이런 설정들을 미리 해두시면 실제 팟을 디플로이 할때는 이 스토리지 클래스만 명시하면 그거를 참고해서 자동으로 볼륨이 프로비저닝 일어나게 됩니다.
그래서 스토리지 클래스를 활용하시면 ebs볼륨을 미리만들필요가 없어지고 그 볼륨 아이디에 PVC를 만드실 필요도 없어지고 PVC를 통해서 PV를 따로 요청하실 필요도 없어집니다. 그리고 default 스토리지 클래스 정의후 팟을 배포할때 따로 클래스 이름도 넣어주실 필요가 없습니다. 그냥 그 디폴트 스토리지 클래스에 맞춰서 자동으로 볼륨이 맵핑이 일어나게 됩니다. 경우에 따라서 여러가지 스토리지 클래스 네임을 만들어서 그때 그때 활용을 하실수도 있고요 일반적으로 이렇게 여러분이 아까 익숙하신 그 PVC에 잇다면 스토리지 클래스 이름만 넣어주시면 이렇게 맞춰서 맵핑이 일어나게 되고 이 PVC를 팟을 배포할때도 같이 함께 사용할수도 있습니다.
오토스케일링
오토스케일링은 쿠버네티스에서 크게보시면 그 팟을 오토스케일링하는 영역이 있을 수 있고 두번째로는 노드를 오토스케일링 하는 부분이 있습니다. 노드라면 저희 ec2클러스터나 혹은 실제 팟이 배포가 되서 러닝이 되는 클러스터를 생각하실수 있고요 이제 당연히 팟이 오토 스케일링이 되기 위해서는 노트에 있는 그 클러스터에 충분한 여유공간이 있어야 노트가 같이 팟이 오토스케일링될수 있을 것입니다.
먼저 팟의 오토스케일링중에서 Horizontal pod autoscaler을 살펴볼건데요 이거는 기본적으로 그냥 스케일 아웃이라고 생각하시면 됩니다. 각각의 쿠버네티스가 수행이 되는 노드에 보통 kubelet과 cAdvisor가 하나씩 데몬셋으로 돌고있고 큐블렛을 통해서 그 매트릭을 매트릭서버로 보내주게 됩니다. 팟이나 컨테이너에 매트릭스를 보내주게 되고 그걸 어그리게이터를 통해서 HPA 컨트롤러로 그 매트릭이 전달이되면 그 미리 생성하신 디플레먼에 있는 레플리카 숫자를 변경하는 형태로 그 HPA가 일어나게 됩니다. 아까 데모에선 리플리케이션 컨트롤러를 말씀드렸는데 일반적으로는 디플로이먼트라고하는 팟컨트롤럴를 더 많이 사용합니다. 그 리플리케이션 컨트롤러는 단순히 팟에 대한 리플리카 숫자만 컨트롤해주는 컨트롤러라고 생각하시면 되는데 디플로이먼트는 거기에 좀더 추가적인 디플로이먼트 관련한 스펙들이 추가되어있는 오브젝트라고 생각하실수 있습니다.
좀더 상세히 보시면 디플로이먼트를 미리 생성하시고 디플로이먼트에는 어떤 팟을 사용할 것인지 리플리케이션이 리플리카 갯수는 몇개로 할건지 이런것들을 선택을 해주게 되어 있고요 거기에서 이제 HPA를 만드실때 타겟 유틸리제이션을 몇프로로 하겠다는 설정을 해주게 됩니다. 그 설정에 맞도록 그 디플로이먼트에 있는 리플리카 숫자가 자동으로 스케일 인아웃이 일어나게 됩니다. 여기는 30초주기는 기본적으로 디폴트 수치인데 변경가능하고 그 쿨다운 딜레이가 있는데 그 매트릭에 따라서 너무 빨리 스케일 인아웃이 일어났을때 예를 들어 스케일 아웃이 갑자기 급격하게 일어났을때 그현상을 쓰레싱이라고 하는데 그거에 맞춰서 이 기본적인 쿨다운을 가지고 HPA 관련한 액티비티가 일어나도록 설정하실수 있습니다. 저희가 설정을 기본적으로 5분이 디폴트인데 이제 운영환경에 맞춰서 너무 빨리했을때 너무 늦게 했을때 장단점이 있기 때문에 참고하시면 좋을것 같고요 그리고 현재의 이어 스테이풀한 그 오토스케일링 버전 1에서는 이버전의 쿠버네티스가 제공하는 API입니다 여기서는 CPU매트릭만 지원을 하는데 V2veta에서는 memory, custom, external, multiple을 다 지원하고 있습니다.
그리고 EKS같은 경우는 베타 API를 다 지원하고 있기때문에 알파버전만 아니면 AWS EKS에서도 다 지원이 된다고 생각하시면 됩니다.
데모시연 (51:00~
https://eksworkshop.com/scaling/test_hpa/
이것도 데모를 짧게 준비했습니다. 먼저 매트릭스서버를 미리 설치해왔습니다. 거기에 스테이터스를 확인하고 샘플 아파치이미지를 기반으로 디플로이먼트를 만들고 HPA를 생성을해서 타겟 유틸리제이션만큼 맞춰서 그 리플리값 숫자가 변경되는것을 확인하는 데모입니다.
보시면 v1베타 매트릭이 매트릭서버 API입니다 그게 잘올라와 있는지 컨디션을 확인하는 부분이고 url에 들어가면 관련한 데모를 실제 해볼수 잇도록 정리되어 있습니다. 이번엔 케이츠 아파치 샘플이미지로 해서 디플레이먼트를 생성하고 서비스까지 노출해서 80포트로 노출을 한 커멘드이고 HPA라고 하는 오토스케일링을 만드는데 그 CPU퍼센트를 50%를 타겟으로 맞추고 in맥스는 1과 10으로 맞춰잇는 설정입니다.
그다음 로드제네레이터를 통해서 이런 샘플로그들을 계속 발생을 시킬거고요 그 이후에 HPA상태를 보면 타겟이 일단 언노운으로 나옵니다. 일단 매트릭를 못받고있고 서버가 지금 못받는과정에서 조금 있으면 200프로로 부하가 치고잇는것을 확인할수 있고 타겟은 50%로 되어있고 팟에 하나만 돌다가 리플리케이션트 컨트롤 숫자가 4개로 바껴서 4개로 돌고있는것을 확인할 수 있습니다. 4개가 도니까 200%의 부하가 더 줄어들게 되겠죠 그래서 115%로 부하가 줄어든것을 확인하실수 있습니다. 이렇게 시간이 좀더 지나면서 8개 까지 리플리카 숫자가 올라간것을 확인할수 있고요 10개까지 늘어났을때 이제 부하가 58%까지 내려간걸 확인할 수 있습니다. 결국 48%까지 내려가면서 타겟 리플리케이션에 맞도록 리플리케이션이 늘어난것을 확인할수 있었고 여기에서 로드를 이제 중지시키면 다시 컨트롤러에 있는 그 리플리카 숫자는 다시 하나까지 줄어드는 것을 확인하는 데모입니다. 그래서 부하가 5%로 줄어들었고 그다음에 리플리케이션 리플리카 숫자도 그만큼 필요가 없어지기 때문에 저렇게 하나까지 팟이 줄어든것을 확인하실수 있습니다. 그래서 한번 나중에 실제 실스을 해보시면 손쉽게 방금 하신 여러가지 설정파일들이나 이런것들을 확인하실수 있을것 같습니다.
일반적인 운영환경에서는 그런 스피얼 유틸리제이션뿐 아니라 다양한 커스텀 매트릭들을 활용하는 오토스케일링을 더많이 하시게 될것입니다. 그런경우에는 커스텀. 매트릭스. 쿠버네티스.io라고 하는 매트릭 api와 호환되는 커스텀 아답터들이 있습니다.
이제 프로메테우스가 대표적인 그 커스텀 아답터입니다. 이제 어그리게이션레이어라고 하는 레이어를 통해서 쿠버네티스 API가 아닌데 그것을 쿠버네티스 API처럼 등록을 해서 어그리게이션 해서 사용하는 형태의 기능이있습니다. 그것을 통해서 프로메테우스를 설치를 하시고 그 아답터를 배포를 해서 커스텀.매트릭.쿠버.io가 해당 커스텀 아답터에 매트릭을 받을수 있도록 설정을 해주시게 되는데 상세한 사항은 url을 확인하세요 https://github.com/directxmain12/k8s-prometheus-adater에 확인하면 어떻게 설정하는지 좀더 상세하게 확인할수 있습니다.
쿠버네티스 실제 도큐멘테이션에 가보시면 이러한 워크스루가 굉장히 상세하게 정리가 되어있습니다. 멀티플매트릭을 사용하는 케이스도 있고 커스텀 매트릭을 사용하는 케이스도 있고 여러가지 다른 시나리오 들이 있는데요 보시면 패킷기반으로 스키퍼 매트릭을 보실수도 있고 팟을 패킷기반으로 보시거나 특정 오브젝트에 어떤 HTTP리퀘스트 갯수를 기반으로 보실수도있고 혹은 로드발란스를 사용하신 보통 로드밸런스에 들어오는 리퀘스트 카운터를 기반으로 많이 분기를 하시는데 로드발란스의 어떤 리퀘스트 카운트를 기반으로 할수도 있습니다.
그리고 혹은 쌓여있는 여떤 외부 익스터널 큐의 갯수를 통해 뒤에 있는 워커들의 팟을 오토스케일링 하시거나 하는 형태로도 활용하실 수 있습니다.
이제 버티칼 팟 오토스케이러는 스케일 업이 업다운 이라고 생각하시면 됩니다. 아까는 스케일 아웃이 일어났는데 조금은 복잡하게 보일수는 있지만 형태는 비슷합니다. 리커맨더 업데이터가 VPA컨트롤러에 있어서 이제 그 리커맨더와 업데이터의 상황을 충족이 됫을때 기존의 있는 팟의 숫자를 늘리는게 아니라 팟의 스펙을 변경을 해주는 오토스케일링입니다. 기본적으로 팟이 일단은 다운이 되고 그다음 변경이되고 다음 올라오게 됩니다. 스케일업은 온라인 중에서 변경되는 형태는 아니고 기본적으로 먼저 VPA같은 경우에는 팟이 정지가 되고 스펙이 바뀐다음 다시 다른곳에 스케일링 된다라고 생각하면됩니다.
VPA 리커맨더와 업데이터를 보시면 매트릭 서버로 부터 받아서 어떤 결과를 리커맨드를 할지 어떤결과로 팟의 스케일을 어떻게 바꿀지 이런거를 설정하는 기능이라고 보시면 되고 업데이터는 실제로 이제 VPA의 오브젝트하고 팟을 비교를해서 리커맨데이션을 실제 팟에 패치하는 기능을 하는 그런 기능입니다. 하지만 VPA는 기존에 사용하고 있던 팟이 말씀드린대로 다운이 될수있기때문에 괸장히 유의해서 조심스럽게 운영을 하셔야합니다. 그래서 팟 디스트럽션 버젯을 사용하시면 동시에 디스트럽션되는것을 방지하실수 있고 이 팟이 다른곳에 배포가 됬을때 클러스터의 스테이터스를 확인하는 다양한 로직들이 필요하게 됩니다. 히스토리 스토리지에는 이벤트하고 유틸리제이션들이 저장되게 되고요
마지막으로 클러스터 오토스케일러에 대해서 설명을 드리려고 합니다. 그것은 실제 팟이 배포가 되는 그밑단에 있는 호스트의 노드들이 스케일 아웃과 스케일인이 일어나는 그런 형태라고 생각을 하실수 있습니다. 설정파일에 클러스트 클라우드 프로바이더를 AWS를 선택을 하시고 그러고 노드에 있는 기존에 생성하신 AWS에 오토스케일링 그룹 그 워커노드의 오토스케일링 그룹을 저렇게 넣어주면 쿠버네티스에서 생성된 클러스터 오토 스케일러가 실제 저기에 맵핑 되어있는 AWS에 있는 오토스케일링 그룹과 연계되서 서로 통신이 되게 되서 스케일 인아웃이 일어나게 됩니다. 동작하는 방식을 이렇게 스케일인이 필요할때는 불필요한 노드를 언리디드로 마크를하고 10분동안 스킬인이 되는 조건이 여러가지가 있습니다 그것들이 다 충족이 되고나서 스킬인이 일어나게 되고 스칼다운이 일어나지 않았으면 하는 노드가 있기 때문에 그럴땐 디스에이블드 어노테이션을 사용하시면 특정노드가 스케일인이 되는걸 방지할수 있습니다. 아까 설명드린 파드 디스트럭선 버젯을 활용하셔서도 마찬가지로 특정 팟이 스케일인이 일어나는것을 방지하시거나 리스트릭션을 방지할수 있는 옵션이 다양히 있습니다. 팟과 노드 모두 리스트릭션을 걸수 있는 옵션들이 있고 컨텐츠가 굉장히 많기 때문에 FAQ에서 살펴보시면 어떠한 조건으로 스케일인이 되는지 아웃이 되는지 보다 상세하게 볼수 있습니다.
1년 4개월간의 직장생활을 끝내고 다시 취업 준비를 시작한지 6개월이 지났다. 취업 준비를 하며 느낀 것은 앞으로 내가 원하는 직무에서 클라우드에 대한 역량은 필수적인 것이라고 생각했다. 그래서 클라우드에 대한 공부를 하며 그것을 증명할 수 있는 자격증을 취득하기로 마음먹었다. AWS, GCP, Azure 여러가지 클라우드가 있었지만 가장 수요가 높고 자료도 많은 AWS의 자격증을 취득하기로 결정했다.
2. 자격증의 선택
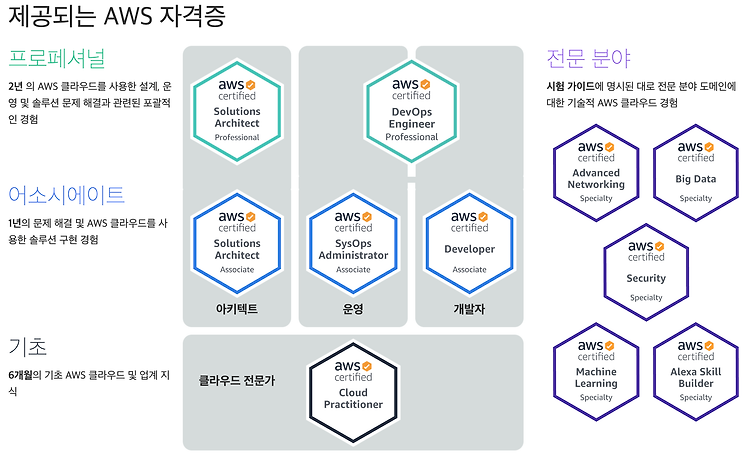
AWS 공인 자격증 종류
AWS의 자격증은 기초, 아키텍트, 운영, 개발자, 전문분야로 총 5가지 분야로 나뉘어 있고 각각의 세부 항목들이 있다.
이 중에서 나는 기초등급의 자격증을 건너뛰고 아키텍트 분야의 AWS Solutions Architect Associate자격증부터 취득하기로 했다.
이후 SysOps Administrator와 Developer 두개를 추가로 취득하고 마지막으로 DevOps Engineer까지 취득해보는 것도 고려하고 있다.
AWS는 배울 수 있는 루트가 굉장히 다양하다. Youtube, 생활코딩, 블로그 등 AWS에 대해서 정리된 자료들이 굉장히 많지만 나는 공부할 때 가장 먼저 책을 사서 읽는 것을 선호하기 때문에 서점에 가서 AWS에 관한 책을 살펴보기 고르기로 결정했다. 정말 다양한 책들이 있었지만 나의 마지막에 나의 눈길을 사로 잡은 것은 '그림으로 배우는 클라우드 인프라와 API의 구조'(히라야마 쯔요시 외 지음) 책이다.
내가 이 책을 고른 이유는 서점에 있던 다른 책들이 클라우드의 도입 이유나 따라하는 실습 구조의 책이었다면 이 책은 Openstack이나 AWS의 내부 구조를 설명해줌으로써 AWS 외적인 기능들이 아닌 그런 기능들을 이해하는데 도움을 줄 것이라고 생각했기 때문이다. 실제로 이 책을 2번 읽었는데 시간 가는 줄 모르고 읽었다. 책에 대한 건 다음에 자세히 다뤄보고 어쨋든 본격적으로 자격증 공부를 시작하기전에 독서하고 공부를 시작했는데 읽고 나서 확실히 AWS에 대한 이해도가 높아졌다는 걸 느낄 수 있었다.
추가로 Youtube나 MSP에서 제공하는 영상을 시청하고 AWS에 대한 기본적인 공부를 끝냈다고 생각해서 자격증을 확실히 취득하기 위해 덤프를 구해 시험 문제를 공부했다. 내가 구한 덤프 문제집의 답안지는 틀린 부분이 많아 문제를 하나하나 AWS백서나 FAQ를 검색해 확실한 답을 찾거나 그래도 해결되지 않는 문제들은 문제 자체를 구글링해서 커뮤니티 정보를 찾아 공부를 했다.
시험 과정중 실습을 하는 부분은 빠졋지만 책을 보며 공부하기 좋아하는 사람이라면 내가 본 '그림으로 배우는 클라우드 인프라와 API의 구조' 책을 보는 것을 추천한다. 실제로 공부 과정중 이 책이 가장 도움되었다고 생각한다.
5. 자격증 취득
시험은 송파역에 있는 테라타워란 곳에서 봤는데 SAA-C01 버전의 마지막 시험날이라 그런지 생각보다 사람이 정말 많았다 대략 20-25명 정도. 시험장에 들어가서 모자, 겉옷, 소지품 모두를 사물함에 넣고 손, 발, 안경, 주머니 검사까지 하고 시험을 볼 수 있었다. 최신 버전의 덤프를 구할 수 있어서 시험은 쉽게 치르고 나올 수 있었다. 후다닥 풀고 빨리나가는 사람이 많더라는....
시험을 제출하면 바로 화면에 합/불 결과가 뜨고 신청한 메일로 결과가 발송된다. CCNA 자격증 취득할때는 따로 PDF파일도 신청하고 했었는데 AWS자격증은 결과가 올라오면 바로 PDF파일도 다운로드가 가능한 점이 마음에 들었다.
6. 앞으로의 계획
홈페이지를 만들어 AWS에 인프라를 구축하고 올려볼까 계획 중이다. 학교 다닐 때 DB를 배워보고 싶어 타과 전공 DB강의를 듣고 프로젝트로 학교 U-campus 홈페이지를 구현한 적이 있다.(4인 조별 과제였는데 다 그만두는 바람에... 혼자서 DB설계 과제부터 프론트, 백엔드까지 제작하고 교수님께 혼자 발표하러 간 경험이 있다. 이때 정말 열심히 만들었는데 컴퓨터 포멧을 잘못하는 바람에 학부 4년간 만들었던 모든 소스코드들이 증발해 버렸다.......)
홈페이지는 spring boot를 배워서 만들어 볼까 생각중이다. 기간은 배우면서 만들어보는 기간까지 1개월 정도로 잡고 있다. 그 후 AWS 올리고 Route53, 모니터링 서버, Terraform이나 CloudFront, 설치 자동화에 대한 부분도 적용해볼 계획이다.